




外付けハードディスク計画、その後
以前、このブログで「AI に外付けハードディスクを与えたい」という構想を書きました。
あれから検討を重ねるうちに、当初の構想がもっと面白い方向に育ってきました。
現在地を共有します。
前回記事:「2 ヶ月前の記憶をなくした AI と、私の『外付けハードディスク』計画」(2026 年 3 月 23 日)
気づいてしまった「散らばり」
当初の構想はシンプルでした。
AI が忘れてしまう過去のやりとりを、外部の記憶装置に貯めておこう。AI に「思い出す」ための仕組みを作ろう。
そのくらいのイメージでした。
ところが、いざ「自分は普段どこに何を書いているのか」を棚卸ししてみました。
すると、想像以上にあちこちに散らばっていたんです。
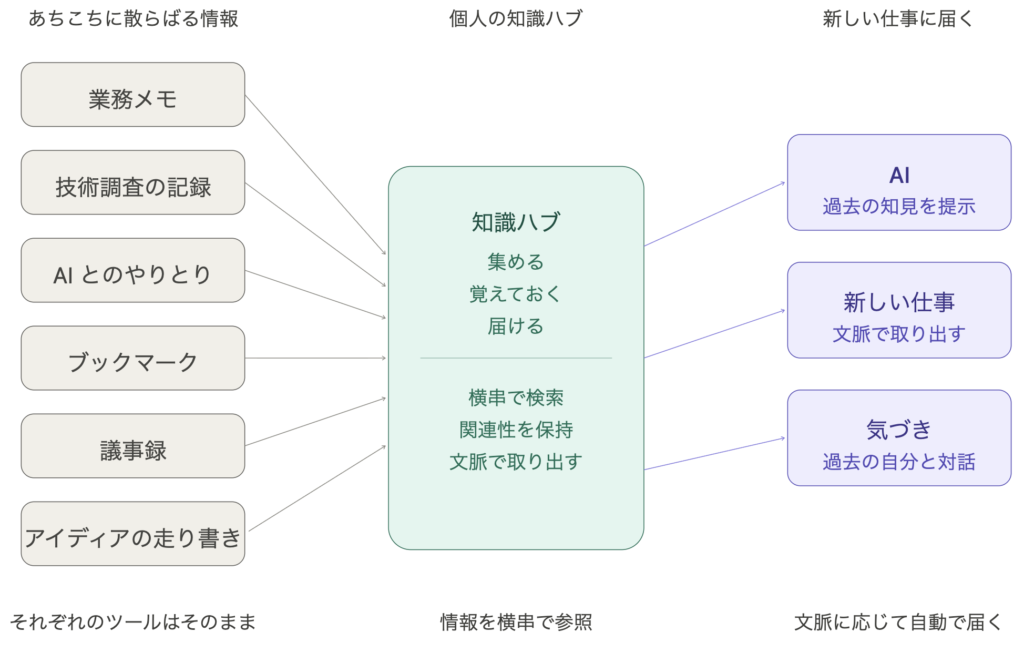
- 業務メモはノートアプリに
- 技術調査の結果は別のツールに
- AI とのやりとりはチャットサービスに
- 気になった Web 記事はブラウザのブックマークに
- 社内の議論はチャットツールに
- アイディアの走り書きは、また別の場所に
どれも、書いている瞬間は「適切な場所」だと思っています。
ノートアプリにはノートアプリの良さがあり、ブックマークにはブックマークの良さがあります。
でも、あとから「あの件、どこかで考えたはずなんだけどな」と探そうとすると、どこにあったか思い出せない。
8 年分、10 年分と積み上がってくると、これは想像以上に大きな損失です。
気づいてしまったんです。
私が本当に欲しかったのは、AI の記憶装置ではありません。
「自分自身の知的活動の集約点」だったのです。
「保管庫」ではなく「ハブ」へ
当初は AI 用語に倣って「Vault(保管庫)」と呼んでいました。
でも、よく考えると違います。
あちこちから情報が流れ込み、必要に応じて取り出され、整理され、また別のところに送り出されていく。
この性質は、保管庫ではありません。
「ハブ(情報の集約点)」と呼ぶのが正確です。
個人の知識ハブ、というイメージです。
ハブには 3 つの役割を持たせます。
ひとつ目は「集める」。
日々あちこちで生まれる情報を、自動的に 1 箇所に吸い寄せます。
手作業で「保存しておこう」と意識しなくても、勝手に集まってくる仕組みにしたい。
ふたつ目は「覚えておく」。
集まった情報を、検索可能で、関連性が見えるかたちに整理しておきます。
ただファイルが置いてあるだけでは、「散らばり」が場所を変えただけになってしまいます。
意味のあるつながりを保ったまま蓄積する必要があります。
みっつ目は「届ける」。
新しい仕事を始める時、関連しそうな過去の知見を、こちらが聞く前に AI が手元に届けてくれます。
「2 ヶ月前に同じ問題で考えたじゃないか」を、AI 自身が気づいて教えてくれる状態を目指します。
個人の発見が、たぶん多くの人の課題でもある
この構想を煮詰めていくうちに、もうひとつ気づきました。
これは私だけの問題ではなさそうです。
業務のあちこちにツールが増えています。
それぞれが便利になり、それぞれにデータが貯まっています。
結果として、個人の知的活動がツール横断で見えなくなる。
情報の検索性が落ちる。
気づかないうちに「あの時調べたはず」を何度もやり直す。
これは、いま多くの知識労働者が直面している共通の課題ではないでしょうか。
ツールを統合する、という発想ではありません。
それぞれのツールは、それぞれの用途に最適化されています。
そのままで良いのです。
ただ、そこに溜まっていく情報を、横串で参照できる「個人の知識ハブ」を 1 つ持つ。
それだけで、知的生産性は大きく変わるはずです。
もし自分で作って運用してみて、本当に「変わった」と言えるなら。
これはいずれ、クライアントに提供できる仕組みになるかもしれません。
当面は自分自身を実験台にして、本当に効果があるかを見極めていきます。
過去のメモが、初めて「読める」状態になる予感
具体的な検証の中で、いちばんワクワクしたことがあります。
過去のノートを救出する目処が立ったことです。
8 年分のメモ。
- 会議の議事録
- 技術調査の記録
- アイディアの走り書き
- トラブル対応のメモ
- お客様との打ち合わせメモ
膨大に積み上がっているのに、必要な時に取り出せない。
長年そういう状態のまま、付き合ってきました。
これがハブに統合されると、状況が一変します。
たとえば、こんなことができるようになります。
- 「3 年前に検討して見送ったあの案件、いまの状況なら成立するかも」が、検索一発でわかる
- 「過去にお客様から指摘されたあの観点、今回も考慮した方がいい」を、AI が勝手に教えてくれる
- 「前にも似たトラブル対応したな」を、AI が過去ログから引っ張ってくる
過去の自分が積み上げてきた知見が、初めて「現役の資産」として機能し始めます。
実装してみないと本当のところはわかりませんが、手応えは確かにあります。
AI 業界の動きも、追い風になっている
このプロジェクトを構想している間にも、AI 業界の動きが日々加速しています。
つい先日も、AI エージェント向けの新しいモデルが発表されました。
関連記事:GIGAZINE「Alibaba が AI エージェント向け新モデル『Qwen3.7-Max』を発表」(2026年5月21日)
https://gigazine.net/news/20260521-qwen-3-7/
チャット応答ではなく、長時間にわたって自律的にタスクを進めることに特化した設計です。
- コードを書いてデバッグする
- 複数のツールを呼び出す
- 何時間も止まらずに作業を続ける
そういう用途のために最適化されたモデルです。
面白いのは、AI モデルの進化の方向性です。
これまでは、単純に「性能を競う」段階でした。
いまは、「用途別に分化する」段階に移ってきています。
- 短い対話に強いモデル
- 長時間の自律作業に強いモデル
- 特定の業務領域に強いモデル
それぞれが棲み分けながら進化しています。
これは、知識ハブのような「AI を業務に組み込む基盤」を作る側にとって、追い風です。
用途に応じて、最適なモデルを選んで組み合わせられます。
重い処理は高性能モデルに任せ、軽い処理は安価で高速なモデルに任せる。
そういう設計が現実的になってきました。
1 年前なら「とりあえず最強のモデル 1 つで全部やる」という発想だった部分が。
いまは「役割ごとに最適なモデルを選ぶ」という発想に変わってきています。
知識ハブを作るタイミングとして、悪くないと思っています。
次のステップ
構想がここまで具体化したので、次は実装フェーズに入ります。
進めかたは、こんなイメージです。
- まず、知識ハブの土台を作る
- 続いて、過去のノート資産を救出して取り込む
- そのあとに、自動化の仕組みを整える
一気に作るのではなく、段階を踏んで進めます。
各段階で得られた感触を確かめながら、次に進みます。
進捗があれば、また続きを書きます。
「個人の知的活動を、ひとつのハブに統合する」という実験が、本当にうまくいくのかどうか。
実体験として記録していきます。
もしこの構想に共感していただけたら、続きを楽しみにしていただけると嬉しいです。
そしてもし「散らばっているのは、もしかして自分かも」と思った方がいらしたら、ご相談ください。ぜひ、一緒に散らばった知を集めに行きましょう。